制程博弈与AI矩阵:深度拆解英特尔IceLake至强的技术突围逻辑
去年春天,当我第一次在实验室里摸到那颗工程样片时,内心其实是复杂的。英特尔憋了太久的10nm,终于要从消费级延伸到服务器领域了。
十年磨一剑:10nm服务器芯片的迟来登场的深层意义
从2014年14nmBroadwell算起,英特尔的制程工艺在服务器领域已经原地踏步了整整六年。当AMD用Zen架构在性能上实现超越,当EPYC系列不断蚕食数据中心市场份额,留给英特尔的时间窗口正在急剧收窄。第三代至强可扩展处理器(IceLake)的发布,本质上是一场技术复仇。
核心数量从28核跃升至40核,这个数字背后并非简单的堆料。10nm工艺带来的晶体管密度提升,让在同等功耗下塞入更多核心成为可能。TDP从205W攀升至270W看似吓人,但换算成每核效率:从7.3W到6.75W,单核能效比提升了约8%。这个账要这么算——性能提升46%,功耗只增加了32%,这笔买卖在工程层面是划算的。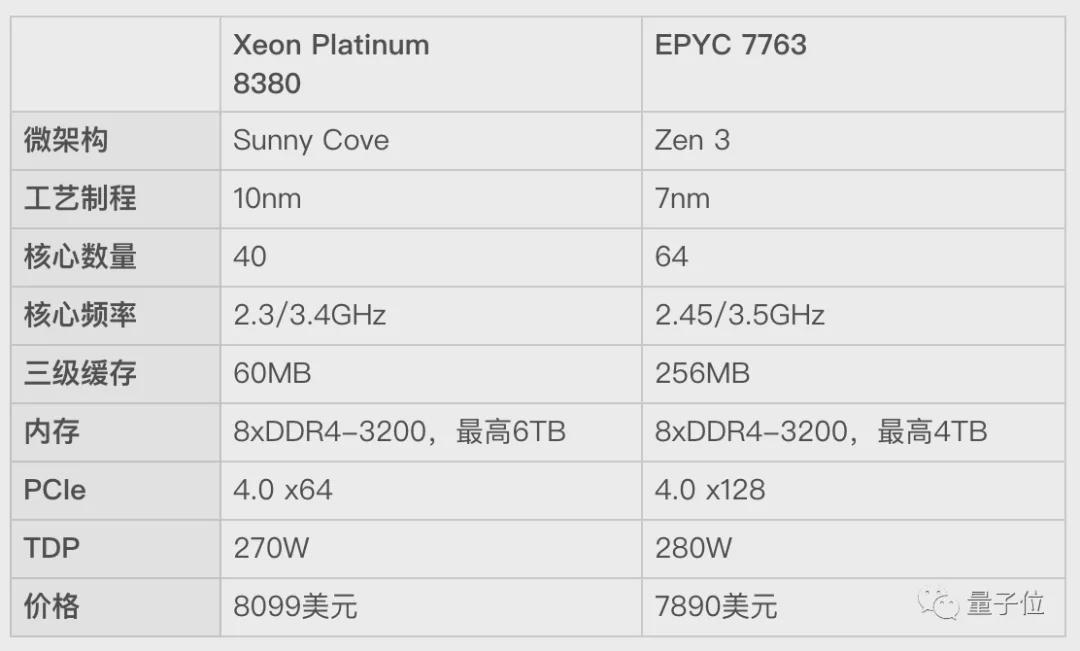
直面AMD:旗舰对撞中的真实差距
AnandTech的实测数据揭示了一个残酷事实:至强铂金8380与AMDEPYC7763单线程性能几乎打平,多线程性能却明显落后。这意味着什么?传统通用计算场景下,AMD的64核心方案依然占据架构优势。Zen3的微架构优化让AMD在并行负载上尝到了甜头。
但这恰恰是英特尔选择差异化竞争的根本原因。当通用性能无法正面碾压时,另辟蹊径才是聪明人的打法。
AI加速:被很多人忽视的杀手锏
DLBoost+AVX-512,这套组合拳的威力被严重低估了。BERT语言处理性能提升74%、MobileNet图像识别提升66%,这些数字背后是硬件级AI指令优化在起作用。更关键的是,当对比对象换成AMDEPYC7763时,某些CV推理任务甚至出现了25倍的性能差距。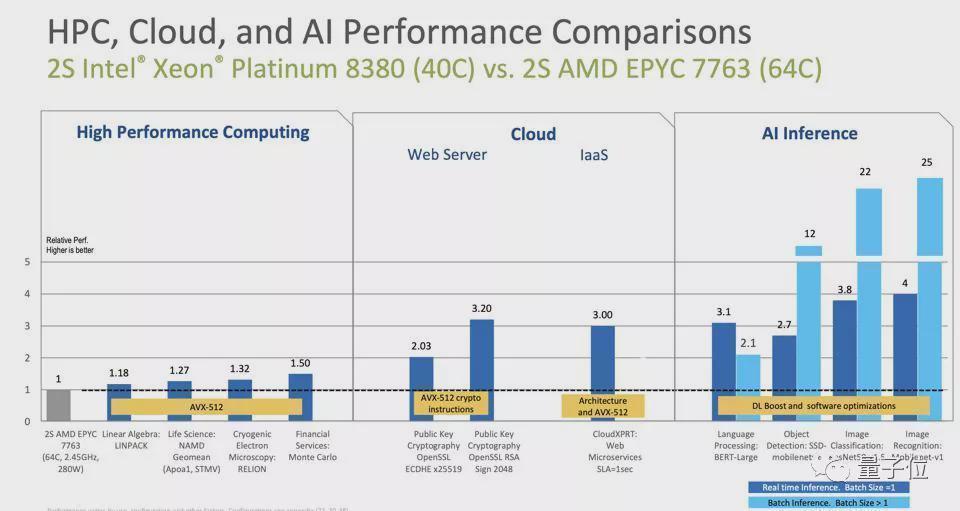
英特尔敢宣称在20个主流机器学习模型上比英伟达A100GPU还强1.3倍,这份底气来自哪里?答案在于:内存带宽与AI加速器的协同优化。当GPU需要跨PCIe搬运数据时,内置AI加速器的CPU可以省去这层开销,在特定推理场景下反而更高效。
生态护城河:配套硬件的协同进化
光有CPU不够。傲腾持久内存200系列的6TB单插槽容量、傲腾P5800X比NAND低13倍的延迟、D5-P5316的5倍QLC寿命——这些配套产品构成了完整的服务器解决方案。阿里云采用傲腾加速存储的案例说明:生态整合能力才是企业采购的核心考量。
技术极客的视角永远聚焦底层真相:制程领先≠性能领先,架构优化才是胜负手。英特尔在AI赛道提前卡位,或许比单纯堆核心更明智。这场博弈,才刚刚开始。


